Statistika Deskriptif: Pengukuran Central Tendency, Variation, dan Position pada Data Tunggal
Berisi penjelasan dan implementasi perhitungan menggunakan Python dan Google Sheets

Pendahuluan
Ketika kita berbicara tentang statistika, itu mengacu pada sejarah awal manusia mengumpulkan data untuk memperoleh informasi. Pada awalnya, statistika hanya digunakan untuk hal-hal yang berkaitan dengan administrasi negara seperti perhitungan jumlah penduduk, perhitungan pembayaran pajak, pehitungan gaji pegawai, dll. Seiring dengan perkembangan teknologi, statistika mulai mulai banyak digunakan diberbagai bidang seperti industri, keuangan, bisinis, dll. Hal ini lah yang mendasari lahirnya ilmu-ilmu baru (gabungan dengan statistika) seperti biostatistika, ekonometrika, dan psikometri.
Kendal dan Stuart (1977) menjelaskan bahwa statistika adalah cabang dari metode ilmiah yang berhubungan dengan pengumpulan data yang dikumpulkan dengan menghitung atau mengukur karakteristik populasi. Sedangkan, menurut Nield (2022), statistika adalah praktik mengumpulkan dan menganalisis data untuk menemukan temuan yang berguna atau memprediksi apa yang menyebabkan temuan itu terjadi. Jadi dapat kita rangkum bahwa statistika merupakan ilmu atau metode ilmiah untuk mengumpulkan, mengatur, merangkum, menyajikan, dan menganalisis data dari suatu populasi termasuk menarik kesimpulan yang valid dan membuat keputusan yang masuk akal berdasarkan analisis tertentu.
Terdapat dua jenis statistika, yaitu statistika deskriptif dan statistika inferensi. Statistika deskriptif merupakan metode tentang pengumpulan data, pengolahan data (meringkas dan menyajikan), menggambarkan dan menganalisis semua data tanpa menarik kesimpulan. Sedangkan, statistika inferensi merupakan metode tentang pengamatan sample untuk menarik kesimpulan atau membuat keputusan terhadap populasi.
Pada artikel ini, kita akan membahas 3 jenis pengukuran pada statistika deskriptif, yaitu pengukuran central tendency, pengukuran variation, dan pengukuran posisi.
Anda dapat mengkases kode Python lengkap yang kami gunakan pada artikel ini di sini dan Google Sheets yang kami gunakan di sini.
Pengukuran central tendency
Pengukuran central tendecy merupakan suatu pengukuran nilai yang dapat digunakan untuk merepresentasikan nilai tengah (central) dari suatu kumpulan data. Terdapat 3 jenis pengukuran central tendency dalam statistika, yaitu mean (rata-rata), median (nilai tengah), mode (nilai yang sering muncul).
Mean
Mean atau rata-rata merupakan penjumlahan dari keseluruhan nilai pada kumpulan data dibagi dengan banyaknya nilai pada kumpulan data tersebut. Secara umum, ketika kita membicarakan tentang nilai rata-rata (mean), hal itu mengacu pada arithmetic mean. Mean untuk populasi dan sample dihitung dengan cara yang sama.


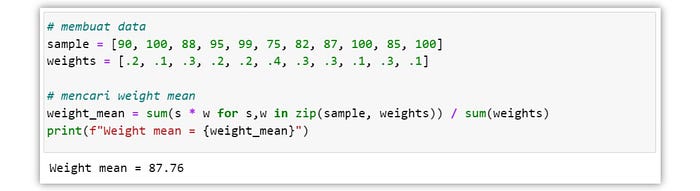
Kemudian, terdapat juga variasi dari arithmetic mean, yaitu weighted mean. Pada weighted mean kita mengasumsikan bahwa setiap nilai memiliki bobot tertentu, sehingga untuk menghitung weight mean kita harus mengalikan nilai dengan masing masing bobotnya terlebih dahulu.

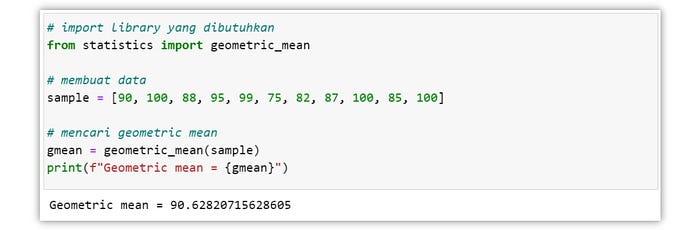
Kemudian, juga terdapat geometric mean. Geometric mean dihitung dengan cara mengalikan semua nilai yang ada pada kumpulan data dan kemudian diakarkan dengan pangkat jumlah dalam dataset tersebut.
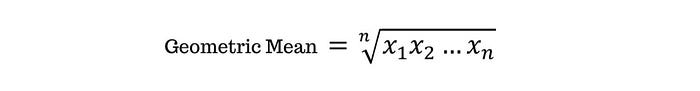
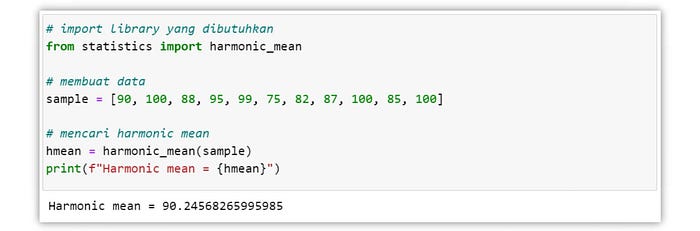
Selain variasi mean di atas, terdapat juga harmonic mean. Harmonic mean dihitung dengan membagi jumlah nilai dalam kumpulan data dengan jumlah kebalikan dari setiap nilai dalam kumpulan data.
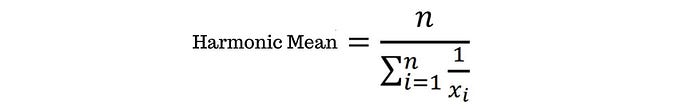
Median
Median merupakan nilai tengah dari suatu kumpulan data. Median didapat dengan cara mengurutkan keseluruhan nilai terlebih dahulu (mulai dari nilai yang terkecil hingga terbesar), setelah itu dicari titik tengah dari kumpulan data tersebut. Jika jumlah kumpulan data genap, maka rata-ratakan dua nilai paling tengah.


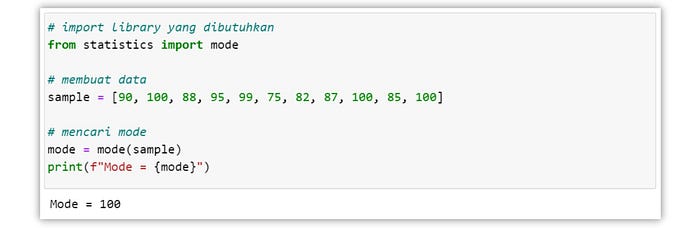
Mode
Mode atau modus merupakan nilai yang sering muncul dalam suatu kumpulan data. Ketika frekuensi kemunculan suatu nilai pada kumpulan data sama, hal itu mengindikasikan bahwa tidak ada mode. Sedangkan bila ada dua nilai yang memiliki frekuensi kemunculan paling banyak disebut dengan bimodal.
Perlu di ingat bahwa ketiga pengukuran central tendency yang telah kami jelaskan tadi memiliki kelebihan dan kekurangan masing-masing. Mean memang cukup bisa diandalkan karena menghitung setiap nilai dari kumpulan data kita, tetapi mean sangat rentan terhadap nilai ekstrem (outlier). Ketika kumpulan data terdapat outlier, kita dapat menggunakan median sebagai alternatif pengganti mean.
Pengukuran variation (Keberagaman)
Pengukuan variation atau dispersi merupakan pengukuran nilai yang dapat digunakan untuk merepresentasikan suatu keberagaman atau sebaran dari data. Dengan ukuran ini kita dapat mengetahui bagaimana data tersebut menyebar dari data yang terkecil hingga yang terbesar atau bagaimana data tersebut berjarak dari pusat persebaran data secara keseluruhan.
Range
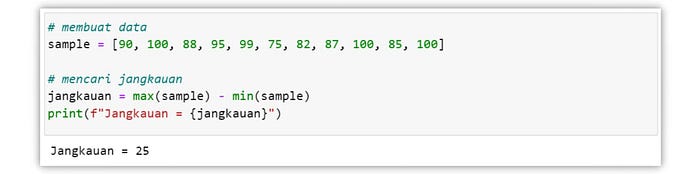
Range atau jangkauan merupakan selisih antara nilai terbesar dengan nilai terkecil dari kumpulan data tersebut. Ketika range bernilai 0, maka hal itu mengindikasikan bahwa keseluruhan nilai dalam data tersebut seragam. Akan tetapi, dalam ukuran persebaran data, range memiliki kekurangan karena hanya menyertakan dua nilai saja dalam proses pengukurannya.
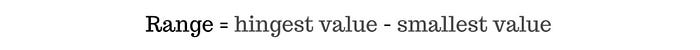
Interquartile Range (IQR)
Interquartike range atau range antar kuartil merupakan nilai yang didapat dengan menselisihkan nilai quartile ketiga (Q3) dan quartile kesatu (Q1). IQR tidak akan terpengaruh oleh nilai ekstrem (outlier), artinya IQR merupakan ukuran variabilitas data yang resisten.
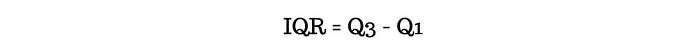

Variance
Variance atau ragam merupakan ukuran seberapa jauh sebuah kumpulan nilai tersebar disekitar nilai rata-rata (mean). Kelemahan utama dari variance adalah nilai yang dihasilkan tidak lagi memiliki skala yang sama dengan nilai pada kumpulan data. Akan tetapi, kelemahan ini dapat diatasi dengan standar deviasi.
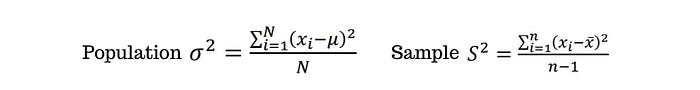
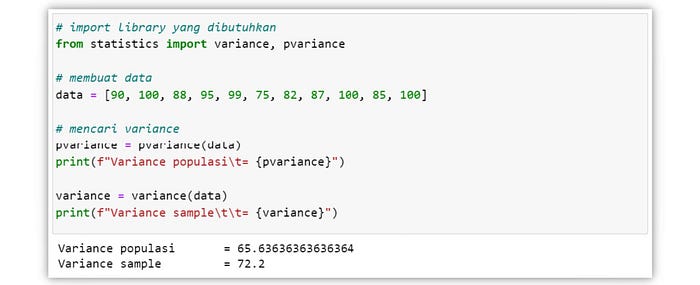
Standard Deviation
Standar deviasi atau simpangan baku merupakan nilai yang digunakan untuk menentukan persebaran data dan melihat seberapa dekat data-data tersebut dengan nilai mean. Standar deviasi didapat dari mengakarkuadatkan nilai variance.

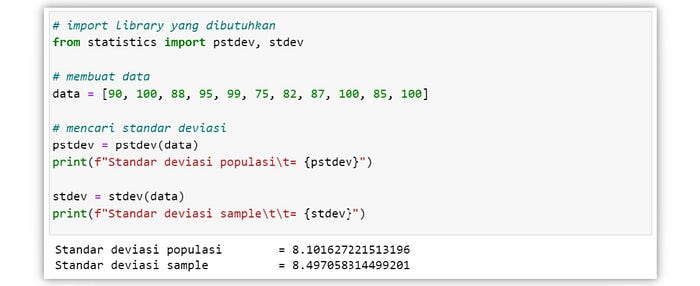
Semakin besar nilai standar deviasi, maka hal itu menunjukan bahwa data semakin menyebar dari nilai mean. Sebaliknya, jika nilai standar deviasi semakin kecil, maka persebaran data akan berada didekat nilai mean.
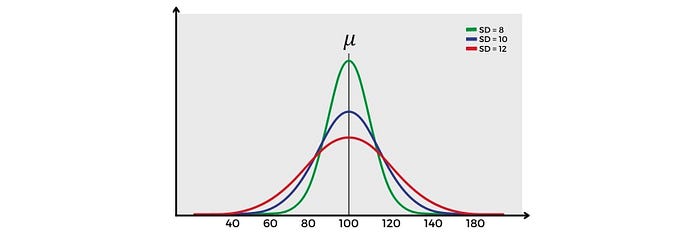
Dapat dilihat pada gambar tersebut, semakin besar standar deviasi maka titik kurva distribusi normal tersebut semakin rendah. Sebaliknya, semakin kecil standar deviasi, maka titik puncak kurva distribusi normal tersebut semakin tinggi.
Pengukuran position
Pengukuran position merupakan suatu pengukuran nilai yang digunakan untuk menentukan posisi relatif dari suatu nilai data (data point) terhadap kumpulan data. Ukuran ini dapat memberi tahu kita apakah suatu nilai merupakan rata-rata, atau apakah nilai itu tinggi atau rendah.
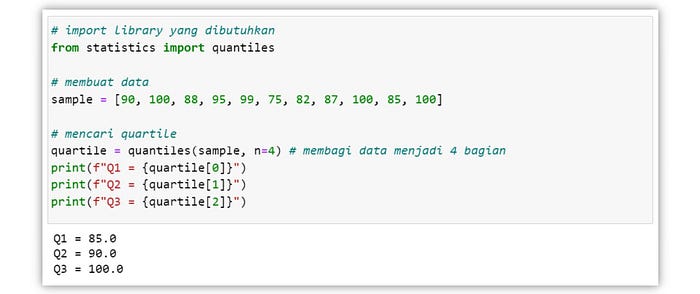
Quartile
Quartile atau kuartile merupakan nilai yang membagi suatu kumpulan data terurut menjadi empat bagian yang sama. Terdapat tiga nilai quartile, yaitu Q1, Q1, dan Q3. Nilai quartile kedua sama dengan nilai mean.

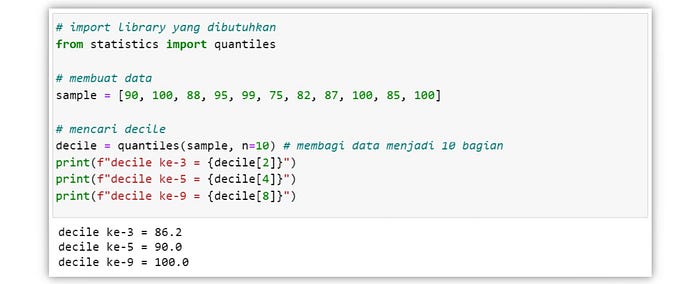
Decile
Decile atau desil merupakan nilai yang membagi suatu kumpulan data terurut menjadi 10 bagian yang sama. Nilai-nilai tersebut dinamankan desil pertama (D1), desil kedua (D2), dan seterusnya hingga desil sembilan (D9).

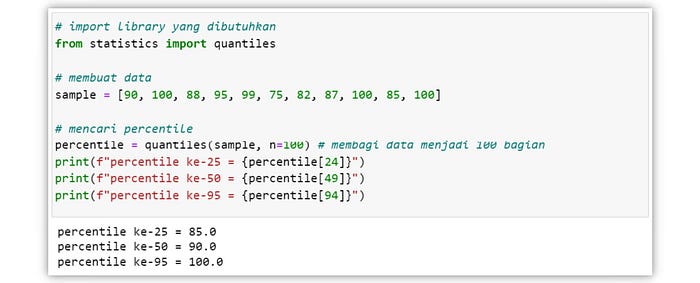
Percentile
Percentile atau persentil merupakan nilai yang membagi suatu kumpulan data terurut menjadi seratus bagian yang sama. Terdapat 99 nilai percentile, mulai dari P1, P2, …, P99. Percentile dapat dimanfaatkan untuk mendeteksi outlier. Ketika suatu nilai lebih kecil dari percentile ke-5 (P5) atau lebih besar dari percentile ke-95 (P95), maka nilai tersebut dapat dikategorikan sebagai outlier.
Statistika deskriptif menggunakan Google Sheets
Implementasi perhitungan statistika deskriptif memang lebih mudah dilakukan di Google Sheets jika tidak familiar menggunakan bahasa pemrograman. Akan tetapi, ketika dataset kita berukuran sangat besar, sangat disarankan untuk menggunakan bahasa pemrogaman seperti Python, Julia, atau R.
Hal pertama yang kalian harus lakukan adalah membuka aplikasi Google Sheets terlebih dahulu di sini. Setelah itu, kalian harus memasukan data yang akan digunakan untuk perhitungan statistika deskriptif. Kalian dapat menuliskan data yang sama seperti yang telah kami implementasikan dengan menggunakan Python.
Setelah selesai memasukan data yang akan digunakan, kemudian siapkanlah area yang akan digunakan untuk menempatkan hasil perhitungannya nanti.

Ada dua cara untuk melakukan perhitungan menggunakan Google Sheets, yaitu memasukan formula (Google Sheets symtax) secara manual dan menggunakan insert function. Untuk menggunakan insert function, pertama klik Insert yang ada pada ribbon. Setelah itu, akan terdapat beberapa pilihan dan kalian harus memilih Function. Terakhir, silahkan kalian memilih fungsi mana yang akan kalian gunakan.
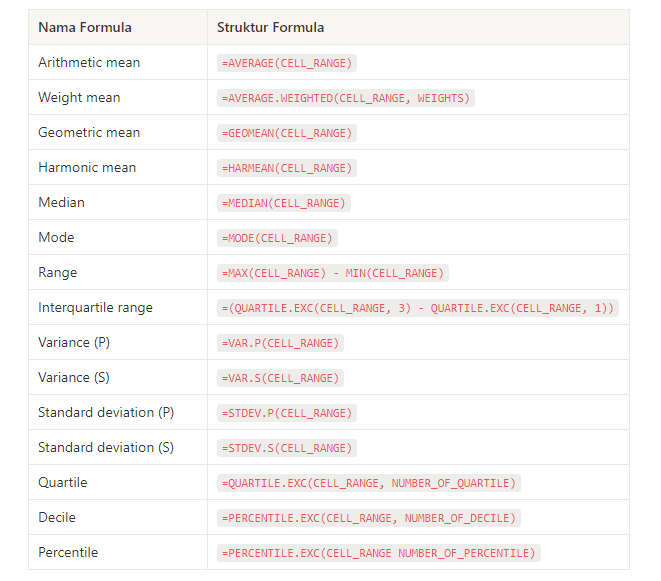
Ketika kita ingin menuliskan formula pada Google Sheets, kita harus mengawalinya menggunakan tanda “sama dengan” (=). Kemudian, tuliskan formula yang akan kalian gunakan, setelah itu beri tanda kurung untuk jangkauan sel atau nilai yang akan dilakukan perhitungan. Secara umum, struktur formula pada Google Sheets terlihat seperti gambar dibawah ini:

Setelah kalian memahami kedua cara tersebut, kalian bebas untuk memilih menggunakan salah satu dari cara-cara tersebut. Untuk formula yang kami gunakan dalam perhitungan menggunakan Google Sheets dapat dilihat pada tabel di bawah ini:
Setelah kalian menerapkan seluruh formula tersebut, hasil akhir dari perhitungan tersebut akan terlihat seperti ini:

Kesimpulan
Statistika deskriptif sangat berguna untuk meringkas sebuah data. Ketika data kita berukuran sangat besar, meringkasnya akan sangat memudahkan kita dalam memahami data tersebut. Perhitungan central tendency sangat berguna untuk menentukan central atau titik tengah dari sebuah kumpulan data. Kemudian, perhitungan variation berguna untuk menentukan penyebaran dan variasi dari sebuah kumpulan data. Sedangkan perhitungan position berguna untuk menentukan posisi relatif dari sebuah kumpulan data.
Python memang sangat mudah digunakan untuk melakukan komputasi (perhitungan statistika). Akan tetapi, jika kita tidak familiar menggunakan bahasa pemrograman, Google Sheets adalah alternatif yang baik.
References:
[1] Nield, T. (2022). Essential Math for Data Science: Take Control of Your Data with Fundamental Linear Algebra, Probability, and Statistics (1st ed.). O’Reilly Media.
[2] statistics — Mathematical statistics functions — Python 3.10.5 documentation. Docs.python.org. (2022). Retrieved 20 July 2022, from https://docs.python.org/3/library/statistics.html.

